How to create AWS RDS cluster with imported SQL dump from S3 using Terraform
aws rds s3 sql terraform devops english
Intro
Recently during some DevOps things I've been working on pipeline creation which allows to test each branch independently from each other. So the original task actually is pretty big, and I'd like to share one of the interesting case in this post. Most probably will write one more a little bit later.
Task
- Create AWS RDS cluster with instance using Terraform.
- Instance should be restored from the existing dump stored on S3.
Solution
Our solution will be based on following technologies:
In this post I will not describe how to setup until TF workspace. Assume that we've already set it up already.
So our first step will be copy init.sql dump to Terraform folder, since Terraform doesn't see anything outside of it.
Locally we will just copy/paste the file, but as I've mentioned above we are going create the pipeline which will do it automatically.
So we need to add copy/paste of our init.sql to our pipeline. In my case I've been using GH Actions:
Copy file action in sandbox.yml file:
name: copy init.sql dump to Terraform folder
run: cp -R ./drupal/getanswers/xtrabackup/init.sql.tar.gzf ./terraform/aws-sandbox/s3-data-upload/init.sql.tar.gz
Remove file action in sandbox-cleanup.yml
- name: remove sql dump from terraform/aws-sandbox folder
run: rm -rf ./terraform/aws-sandbox/s3-data-upload/init.sql.tar.gz
Note: make sure that, sql dump has been created using Percona XtraBackup tool, otherwise RDS cluster will not be restored from S3.
Below I'll provide my rds.tf config. Make sure that you will define variables by yourself.
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket
resource "aws_s3_bucket" "s3" {
bucket = "s3-bucket-${var.your_name}"
acl = "private"
tags = {
Name = "S3 Bucket with init.sql dump"
Environment = var.workspace
}
}
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket_object
resource "aws_s3_bucket_object" "init_sql" {
bucket = aws_s3_bucket.s3.id
key = "init.sql.tar.gz"
source = "${path.module}/init.sql.tar.gz00"
etag = filemd5("${path.module}/init.sql.tar.gz00")
}
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/rds_cluster
resource "aws_rds_cluster" "sandbox" {
cluster_identifier = "aurora-mysql-cluster-${var.your_name}"
engine = "aurora-mysql"
engine_version = "5.7.mysql_aurora.2.07.5"
port = 3306
availability_zones = slice(data.aws_availability_zones.available.names, 0, var.aws_az_count)
master_username = var.rds_master_username
master_password = var.rds_master_password
skip_final_snapshot = true
apply_immediately = true
lifecycle {
ignore_changes = [engine_version]
}
# this is important peace which tell TF that this cluster should be restored from S3 dump file
s3_import {
source_engine = "mysql"
source_engine_version = "5.7"
bucket_name = aws_s3_bucket.s3.id
ingestion_role = aws_iam_role.s3_rds.arn
}
}
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/rds_cluster_instance
resource "aws_rds_cluster_instance" "cluster_instance" {
count = 1
identifier = "aurora-cluster-instance-${count.index}"
cluster_identifier = aws_rds_cluster.sandbox.id
instance_class = "db.t3.small"
engine = aws_rds_cluster.sandbox.engine
engine_version = aws_rds_cluster.sandbox.engine_version
lifecycle {
ignore_changes = [engine_version]
}
}
Actually this step goes before step 2 in the TF execution pipeline, but we will keep it here just for better understanding. Terraform is smart enough to resolve resource executions if they depend on each other.
File security.tf with appropriate IAM Roles and permissions:
resource "aws_iam_role" "s3_rds" {
name_prefix = "rds-s3-integration-role-"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "s3_rds" {
name_prefix = "rds-s3-integration-policy-"
role = aws_iam_role.s3_rds.name
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketACL",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::${aws_s3_bucket.s3.bucket}"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload"
],
"Resource": "arn:aws:s3:::${aws_s3_bucket.s3.bucket}/*"
}
]
}
EOF
}
Result
Run
terraform planterraform apply
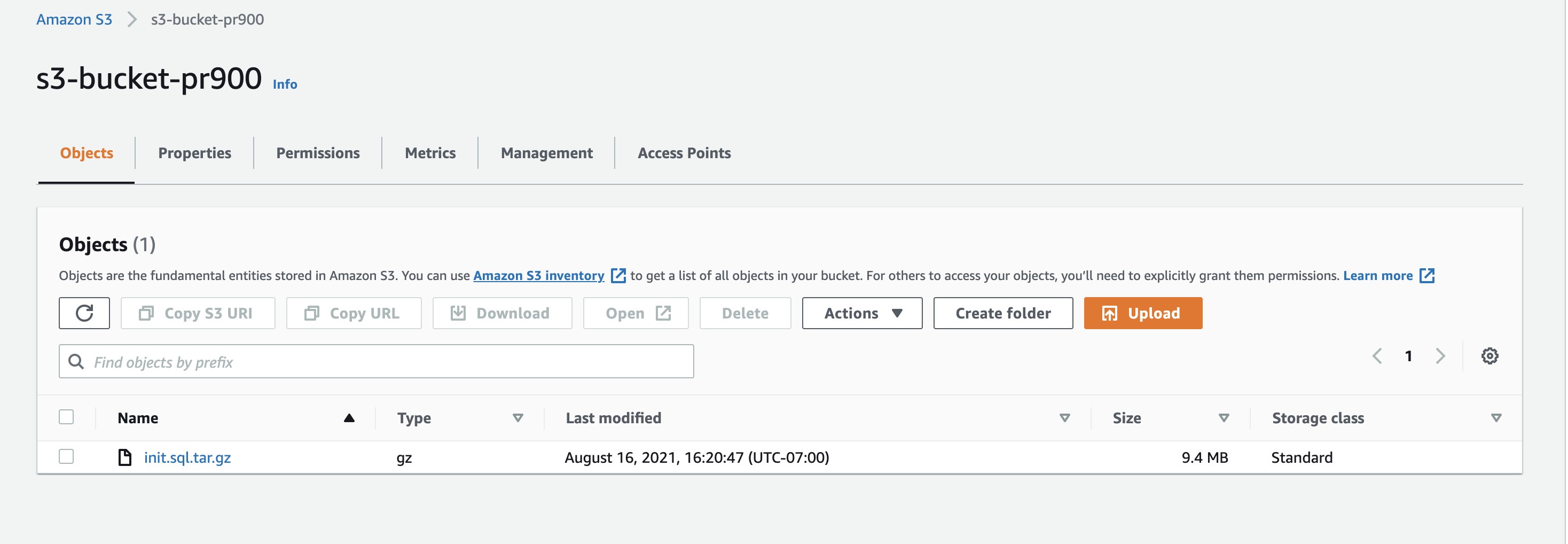
if your setup is correct you should be able to see follow results on AWS Dashboard:
S3
RDS

Happy creating your own RDS cluster on AWS with Terraform! :)